
Swwing
你好啊,我是Swwing
这里或许是我的Blog
核心方向
技能维度评估
基于 0-10 分的自我评估展示能力分布
评分说明:0-3 较低,4-7 中等,8-10 优秀
能力(8):能力方面,本人掌握的知识较多且知识面广,擅长新时代的新兴技术,能应用到技术生产的活动上。但是资历尚浅,需要更多的时间来提升自我能力。
沟通(9):沟通方面,本人沟通能力强,性格开朗且愿意开口与人交流建立关系,行事有准则但不僵硬,富有同理心但也敢说不。
合作(8):合作方面,本人擅长跨部门合作交流,有相关的实习经历和专业经历,擅长编排调度和规划管理。但是如果是接触全新的环境,对于部门之间的协同效益需要时间了解和适应。
设计(6):设计方面,本人较为普通,具有基本的审美能力,不过在擅长的方面具有独到的理解。
创新(7):创新方面,本人思维敏捷,擅长多视角分析和类比推理,逻辑清晰,时常以全新的视角看待身边的事物。
学习(10):学习方面,本人学习能力强,自学web语言耗时两周创建个人网站,一年时间自学日语达到N1水平,对于新事物的接受能力强,乐于学习新知识和新技术。
能力展示
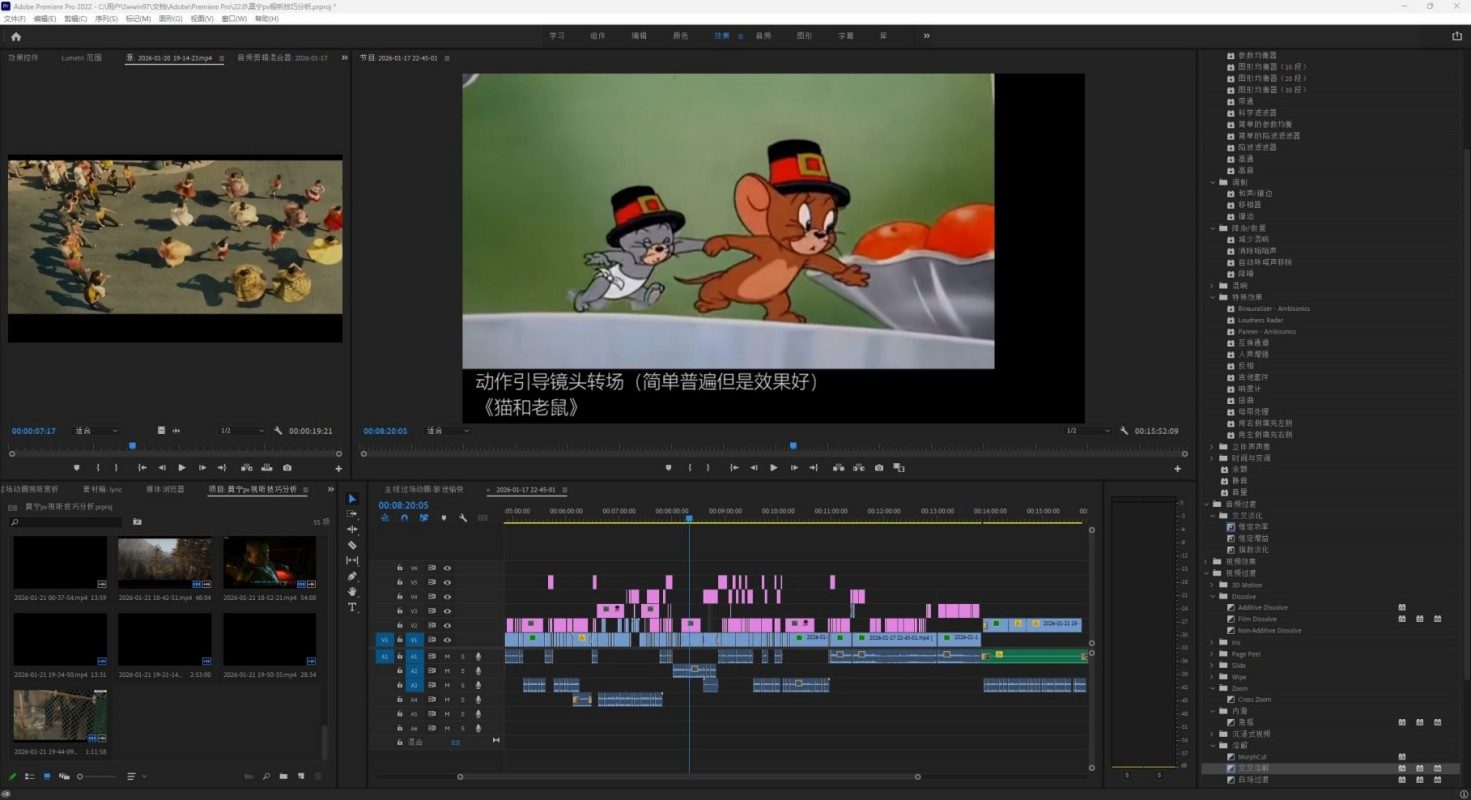
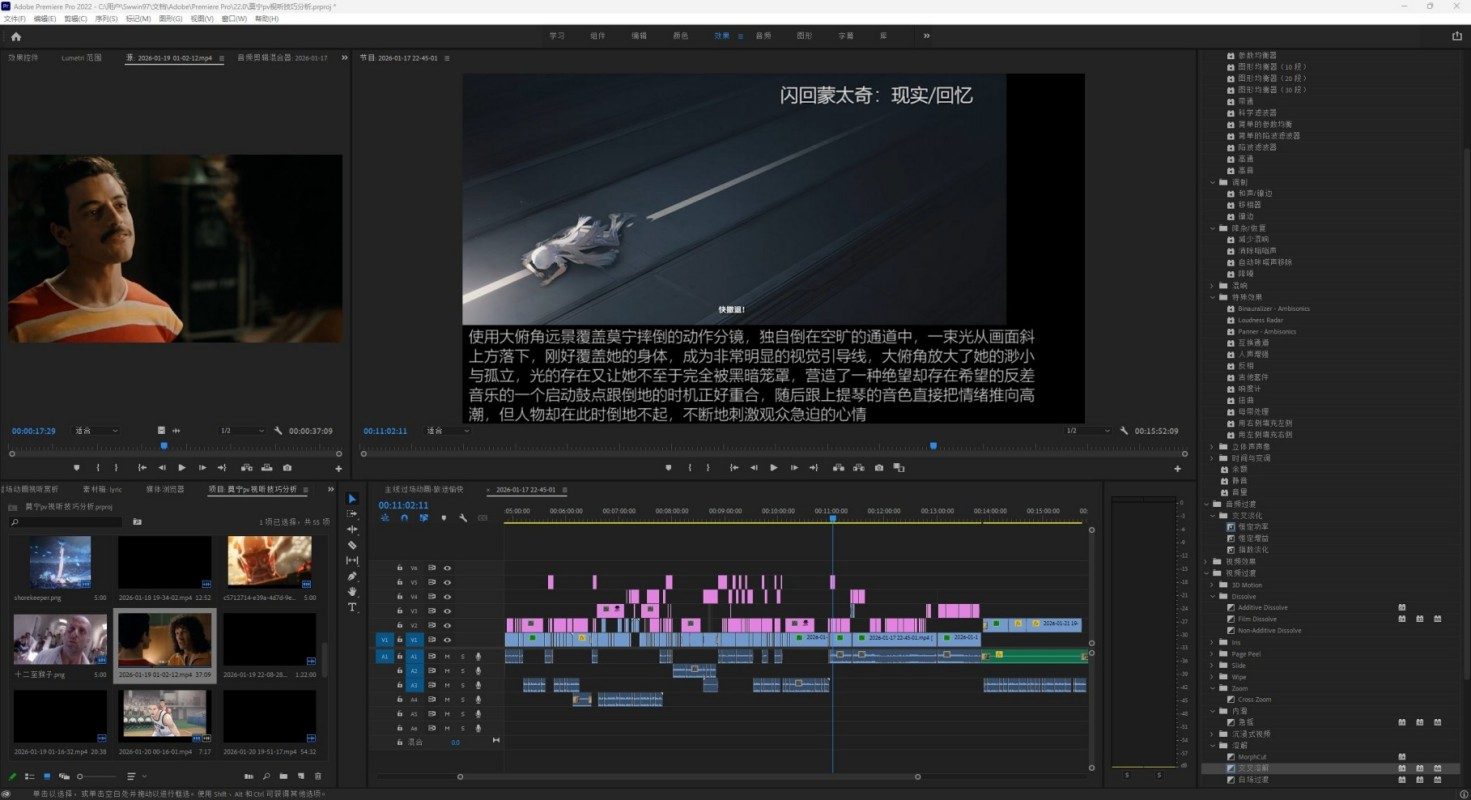
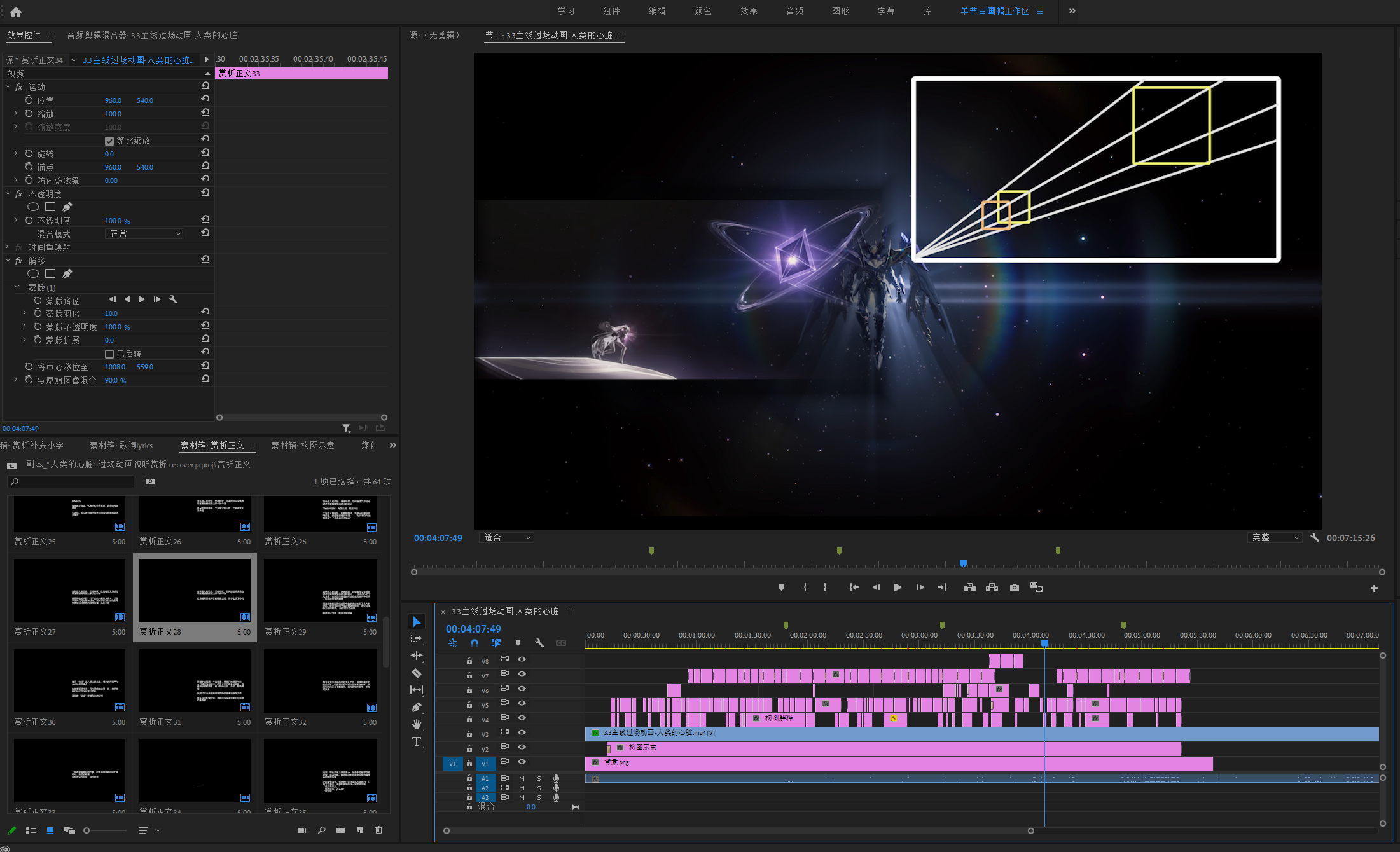
视频剪辑与视听分析

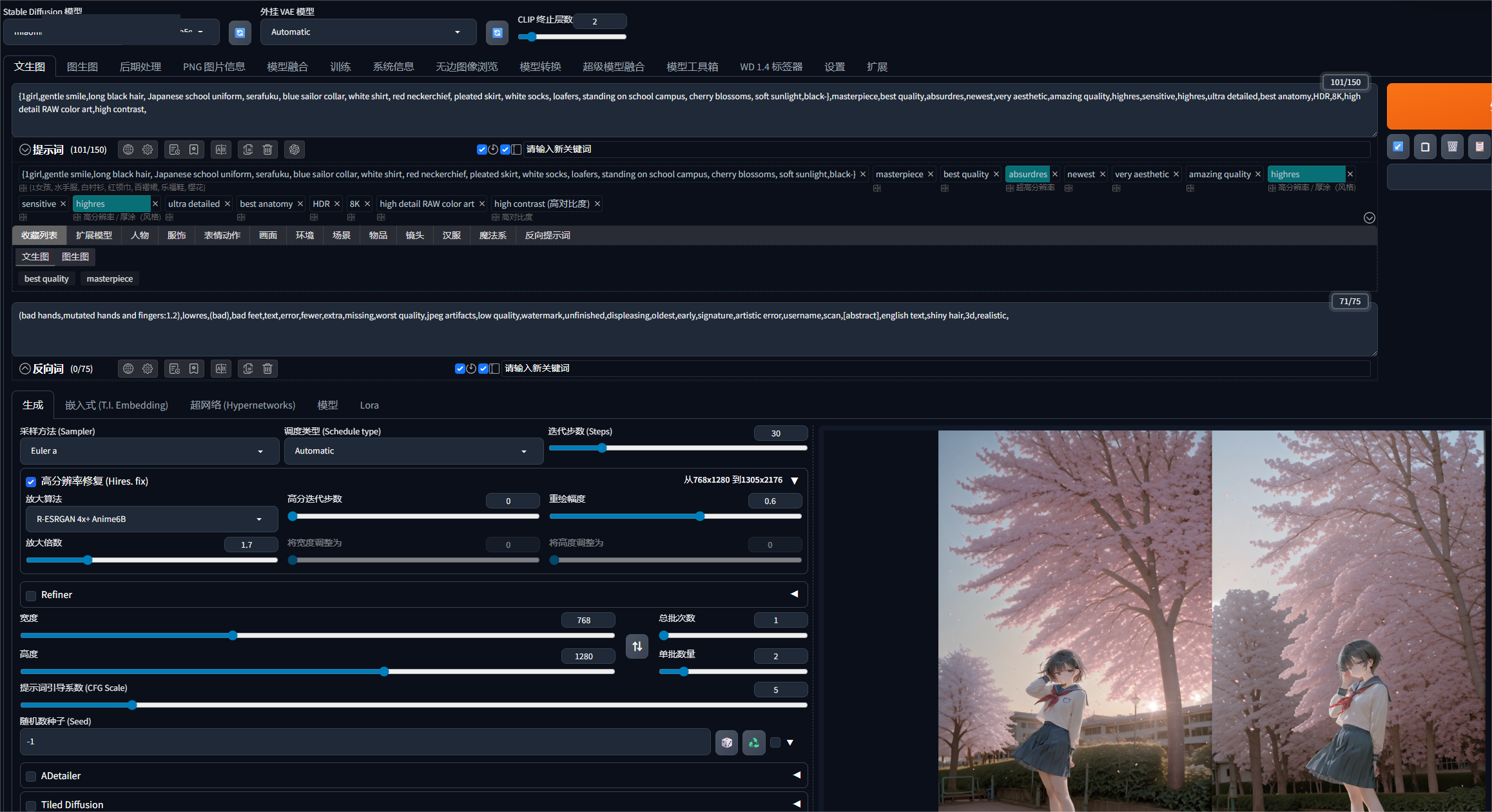
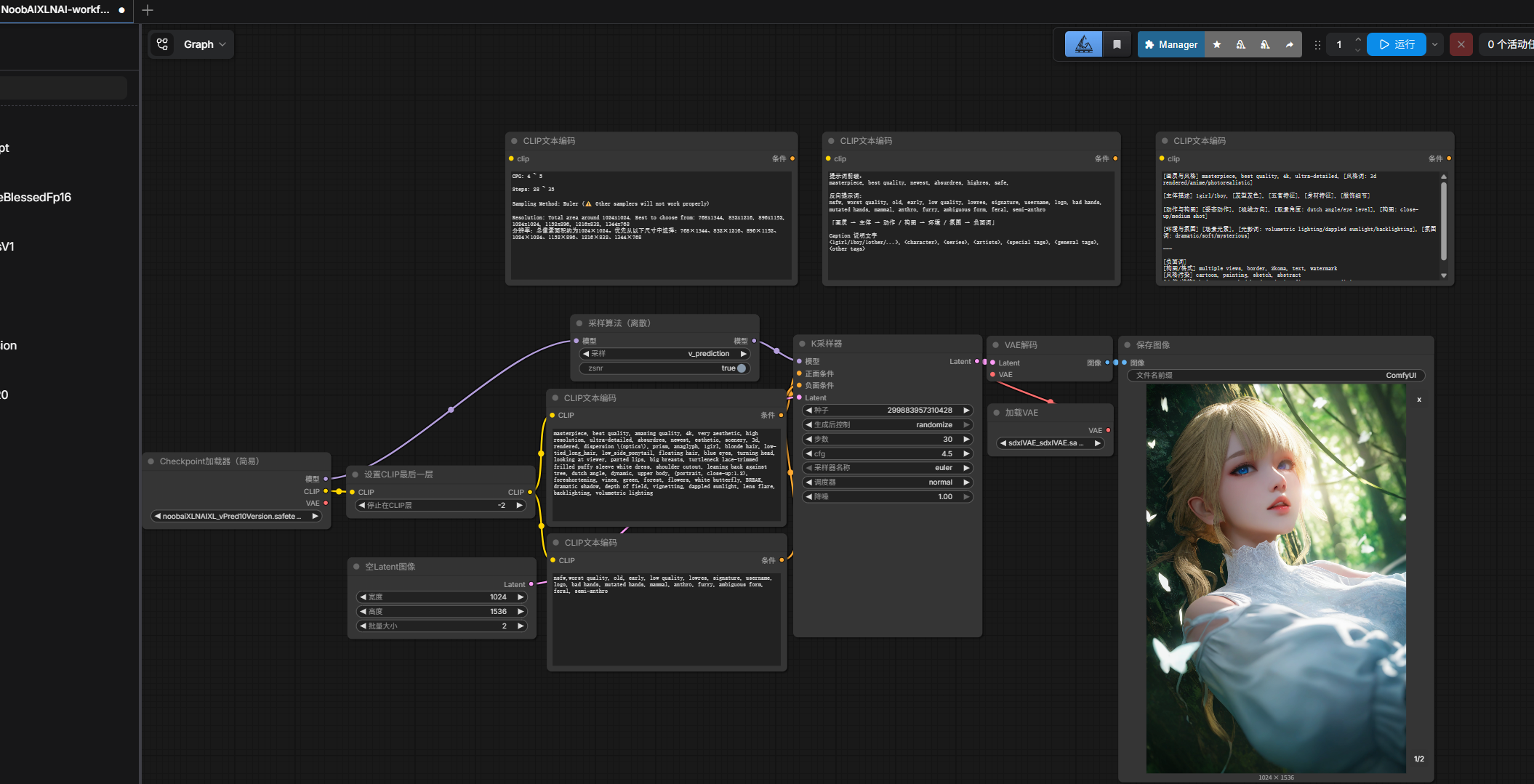
人工智能生成内容(AIGC)












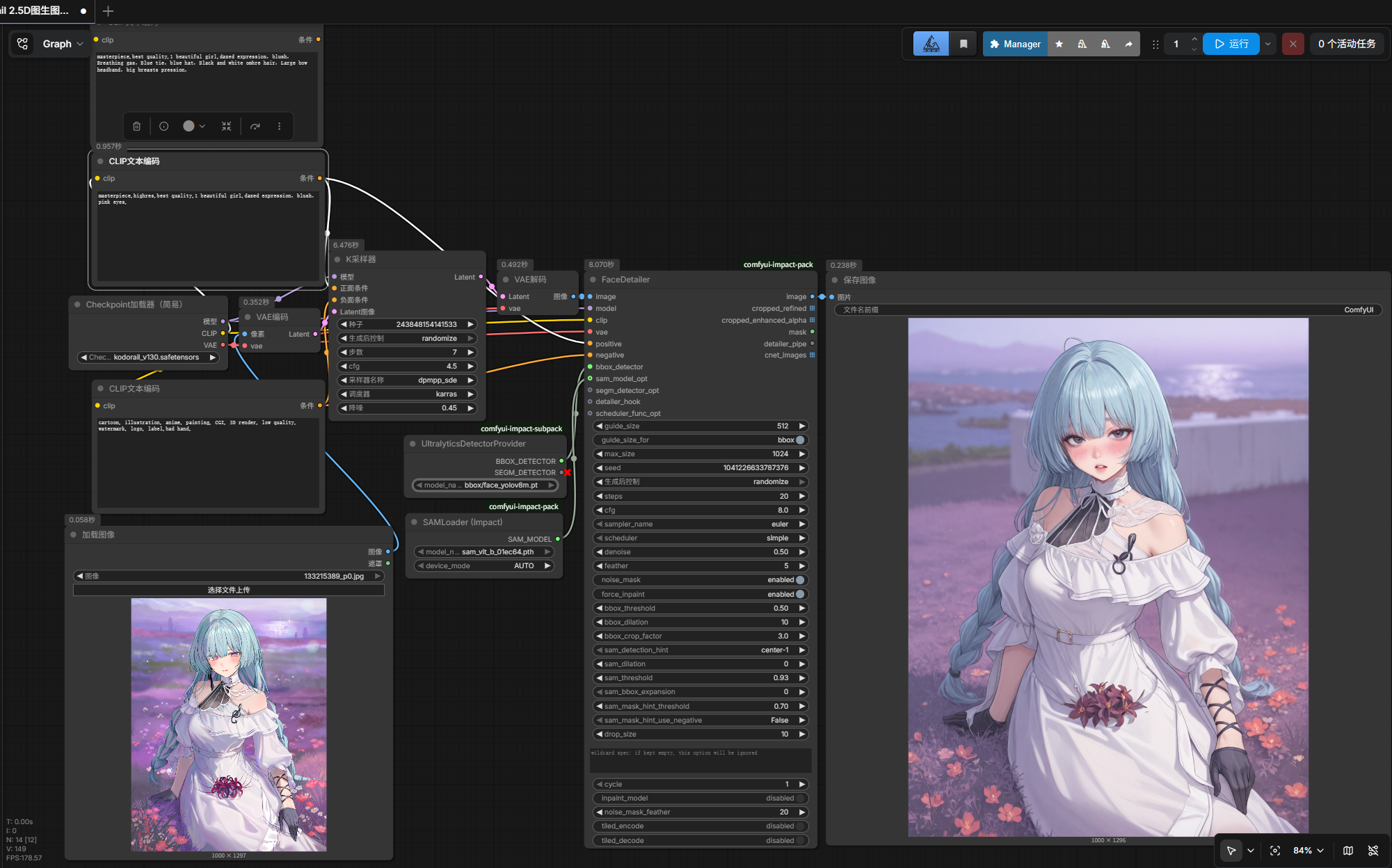


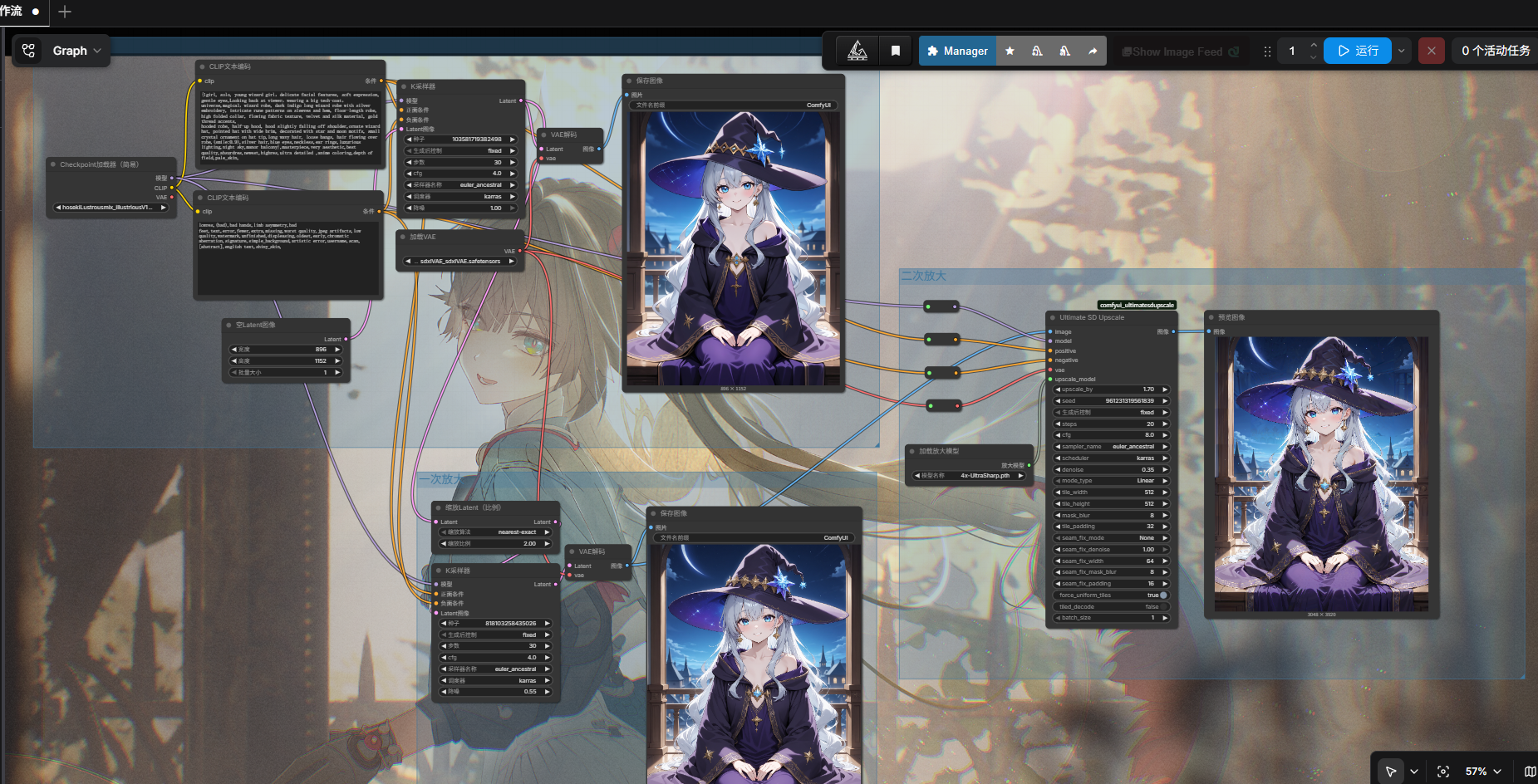

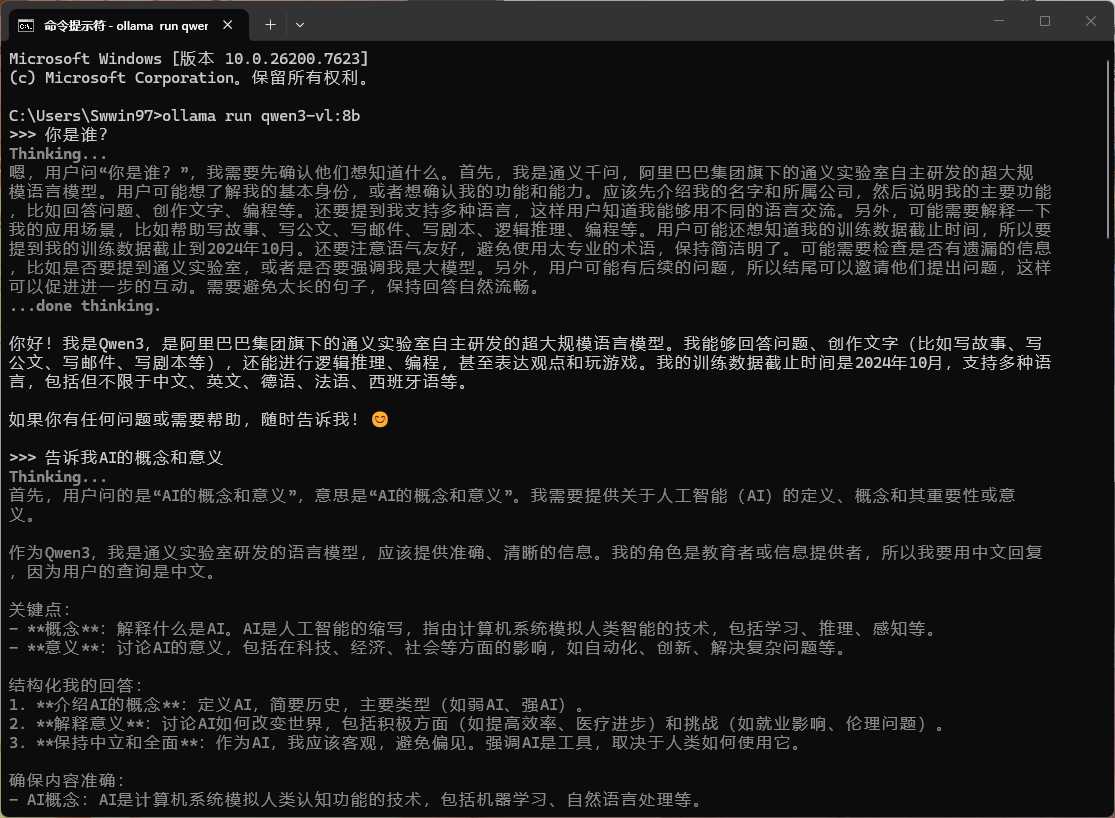
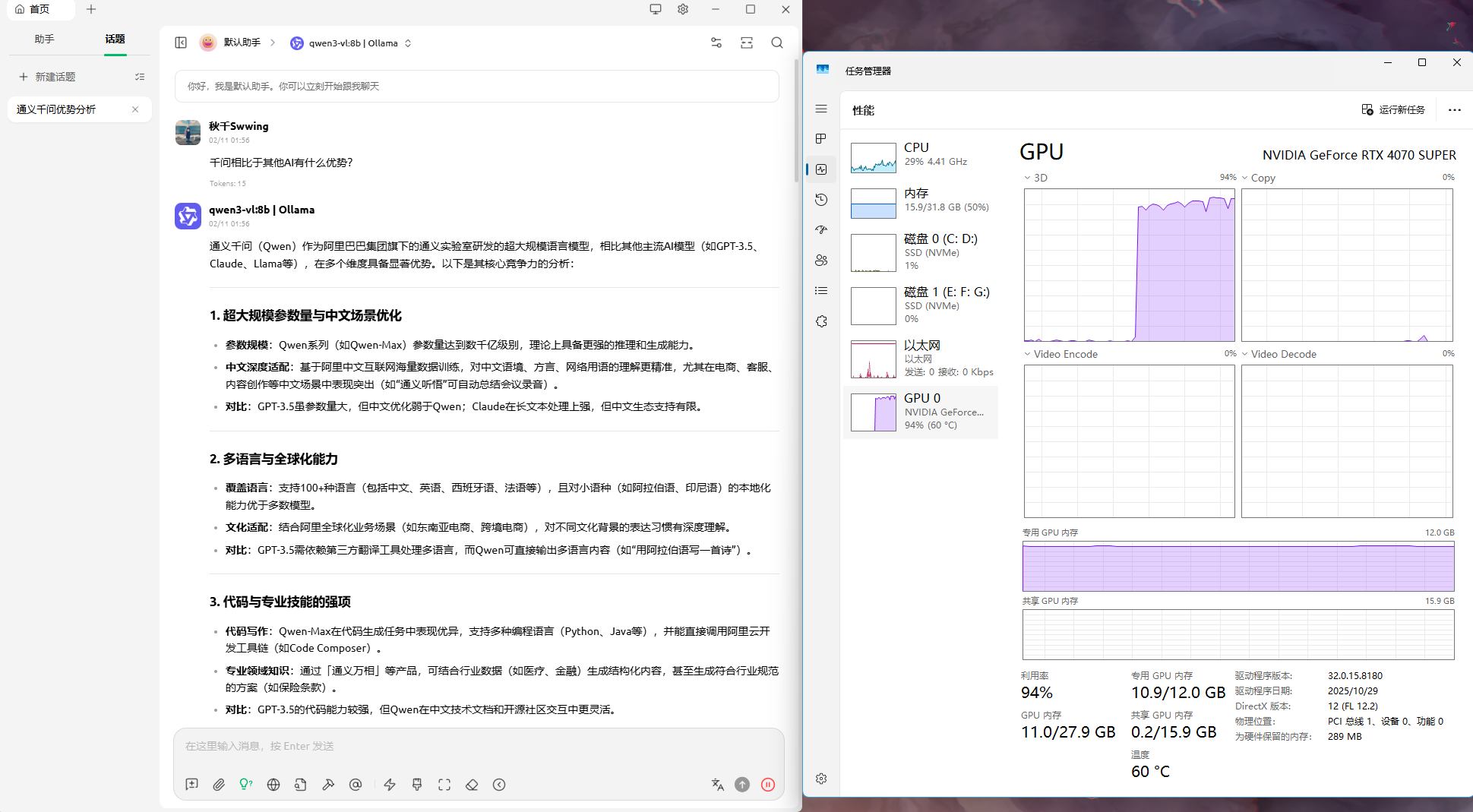
通用大模型开发
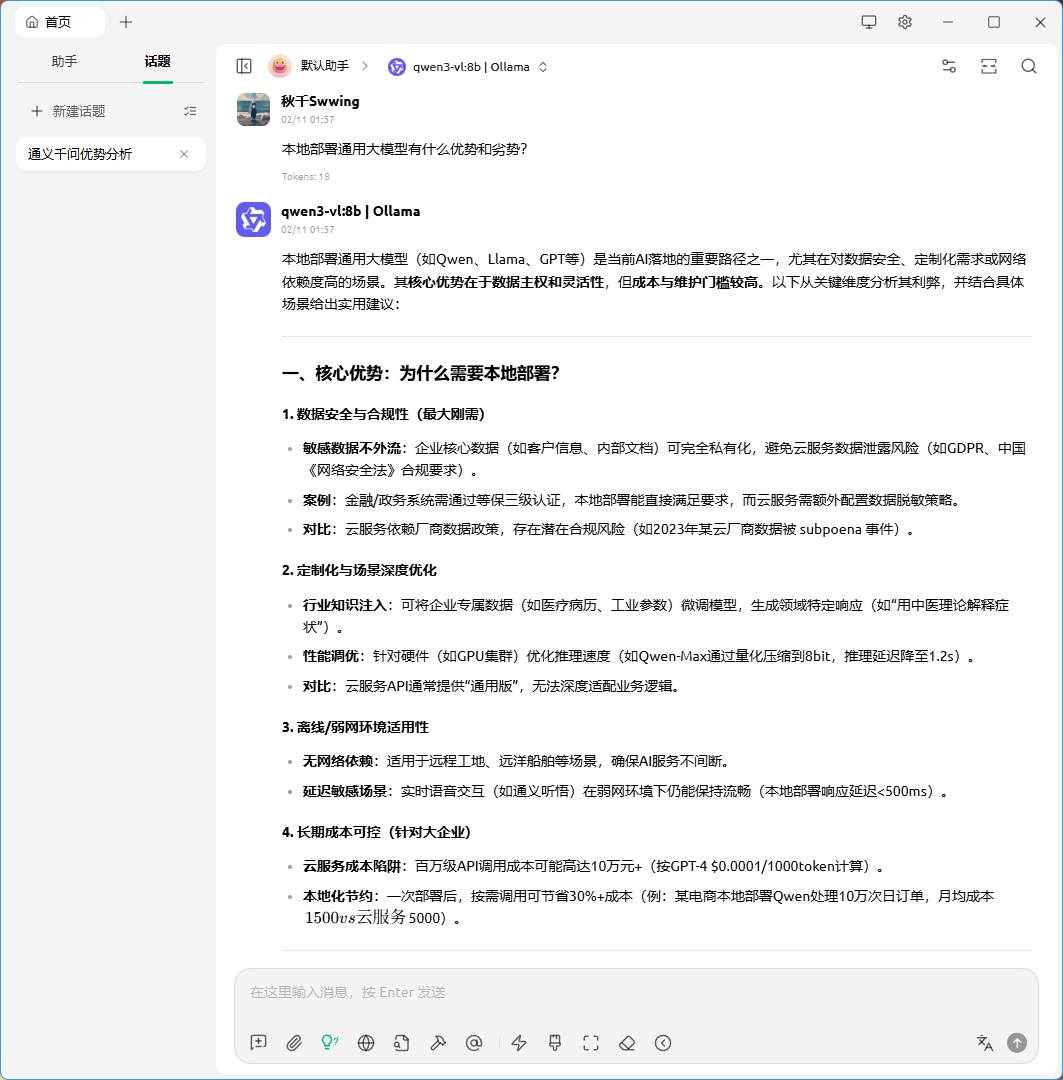
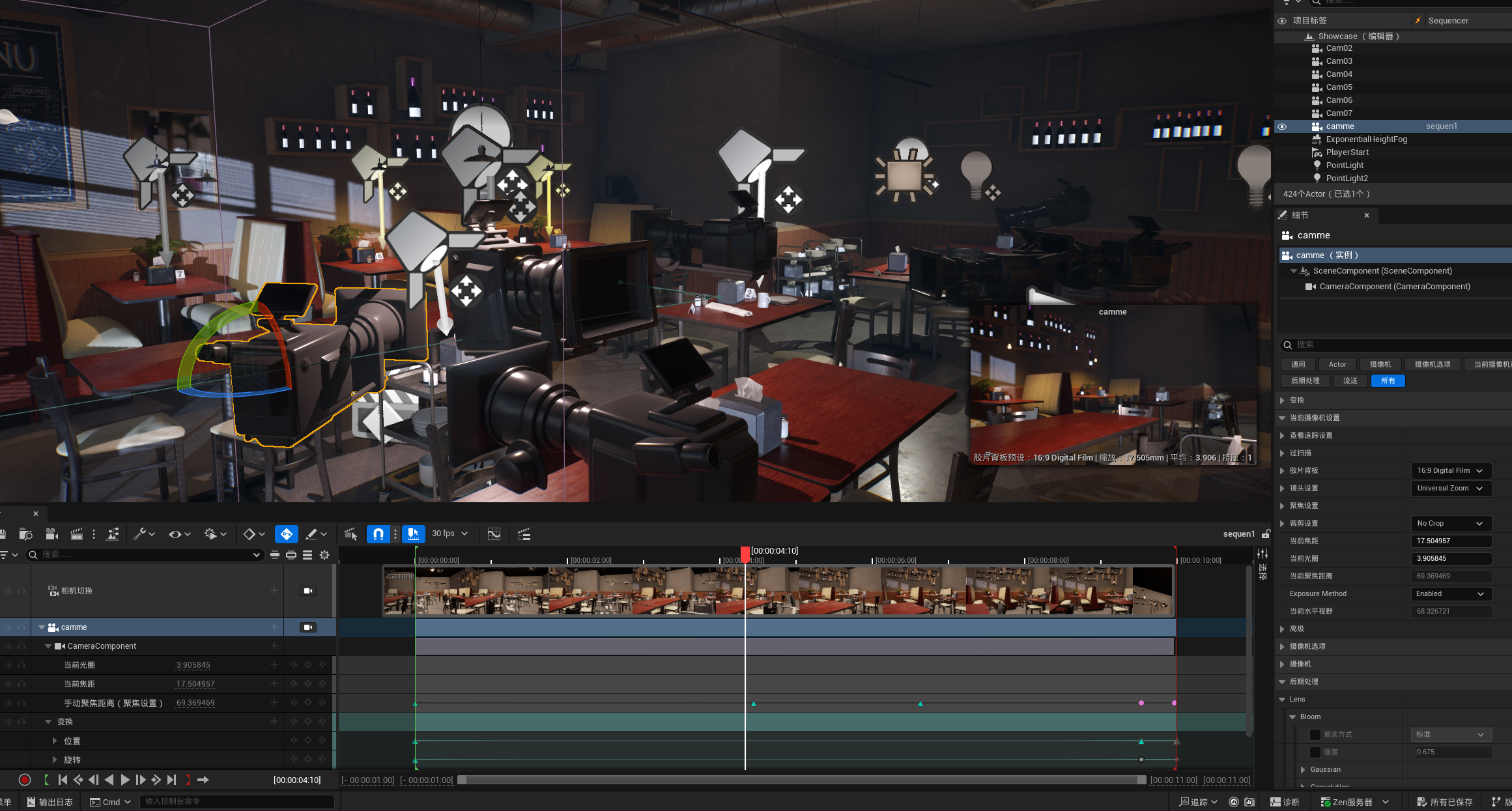
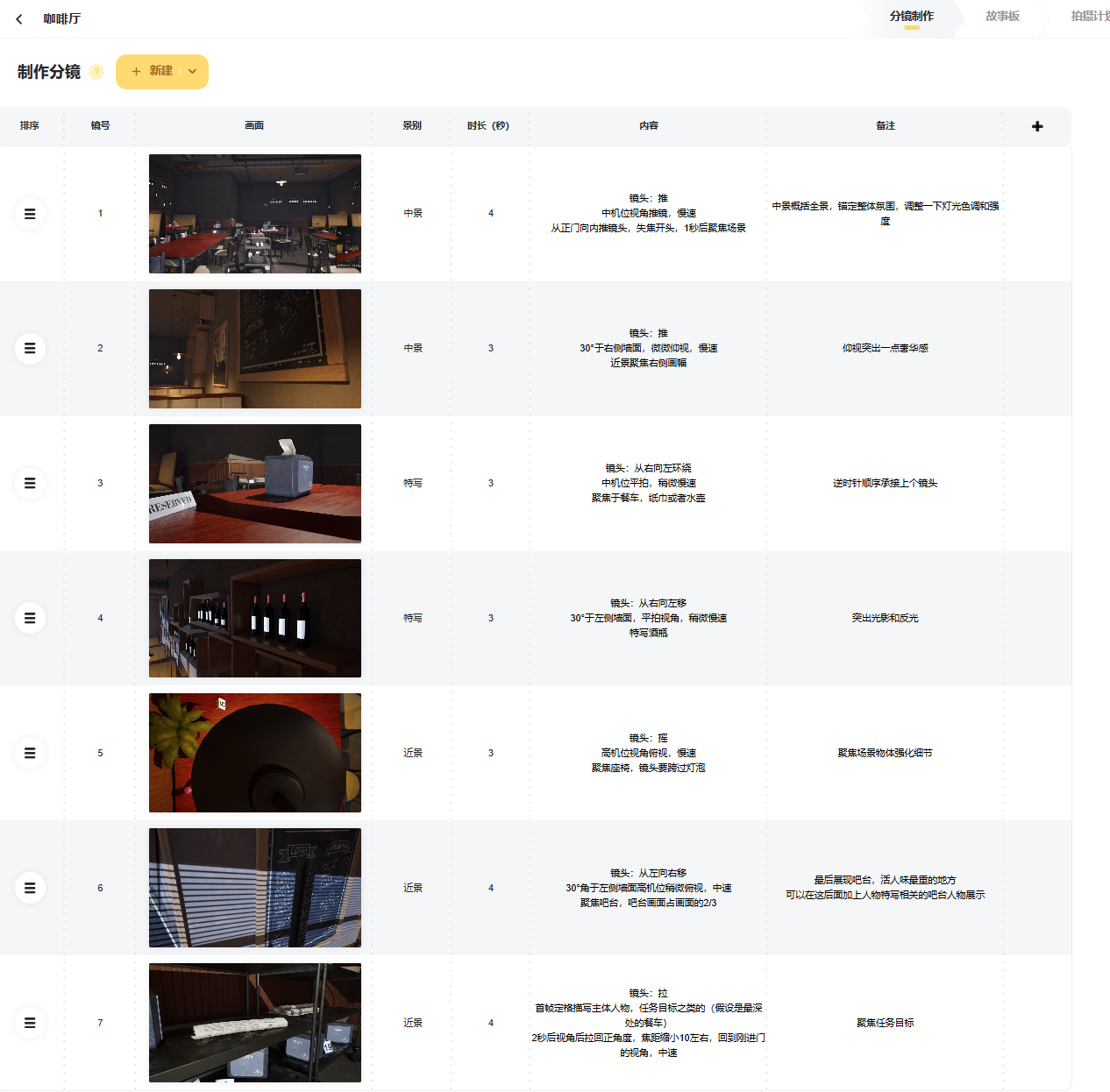
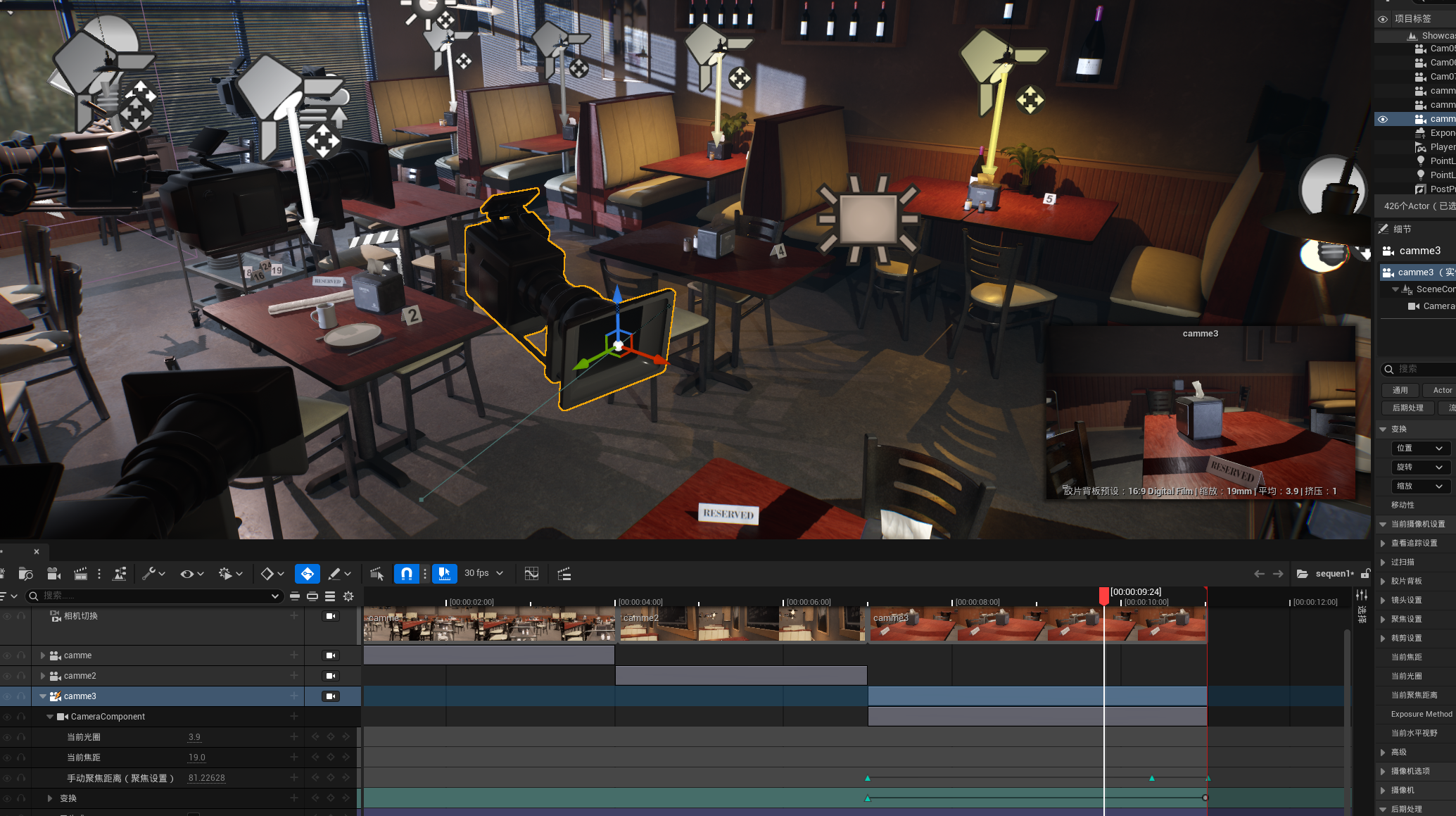
虚幻引擎UE5

零基础自学建站流程
语言能力
